Hay muchos términos que podrían describir las diversas facetas de la tendencia secular de crecimiento de la analítica de datos y la inteligencia artificial, y también hay diferentes matices en las definiciones de esos términos.
A los efectos de este artículo, expondremos la forma en que definimos cada categoría descriptiva. Hemos elegido específicamente el orden en el que compartimos estos términos porque los vemos como graduaciones desde el nivel base al nivel más avanzado, es decir, inteligencia real, de tipo humano, o IA. Esto es, por supuesto, sólo una lente a través de la cual podemos ver esta industria.
Ciencia de los datos: la ciencia de los datos es una actividad en la que todos hemos participado. Históricamente, ha sido la acción de recolectar puntos de datos e insertarlos en una hoja de cálculo de Excel, de la cual hemos obtenido conocimientos. En cierto sentido, todos somos científicos de datos en diversa medida, y en base a esta realización, empresas como Alteryx, han diseñado plataformas con el objetivo de reemplazar el análisis de datos de la hoja de cálculo de Excel para la persona media (así como para la persona más avanzada). En resumen, la ciencia de los datos es simplemente el acto de recopilar datos y utilizar diversas herramientas de software para generar conocimientos a partir de ellos.
Machine learning: el machine learning o aprendizaje automático, gira en torno a la idea de utilizar software (especialmente algoritmos) para crear "programas capaces de aprender". Ejemplos de aprendizaje automático incluyen la capacidad de Amazon para predecir lo que te puede gustar en base a lo que has comprado en el pasado, la capacidad de Netflix para predecir lo que puedes querer ver en base a lo que has visto o navegado en el pasado, y la capacidad de Facebook para predecir con quién puedes querer conectarte en base a tu red de conexiones ya establecida. Es la idea de que a medida que se introducen más datos en el programa de software, o algoritmo, el programa se vuelve más inteligente y capaz de generar mejores conocimientos dentro de un entorno determinado. Discutiremos esta idea con bastante profundidad más adelante.
Inteligencia Artificial: el santo grial de todo esto. La inteligencia artificial suena intimidante, pero es muy simple. La inteligencia artificial es sencillamente la réplica de la mente humana y su capacidad de predicción, pero con la capacidad de considerar un número infinito de puntos de datos de forma simultánea y sin descanso, para identificar patrones y crear predicciones. Al considerar la inteligencia artificial, simplemente debemos pensar, "la función principal de la mente humana es recoger datos, almacenar datos, y luego tomar decisiones predictivas basadas en esos datos". Nuestro objetivo en la ciencia de los datos, el aprendizaje de las máquinas y, en última instancia, la inteligencia artificial es crear programas de software que realicen la función de la mente humana a escala masiva (es decir, considerando cuatrillones, y mucho más allá, de puntos de datos simultáneamente) y sin necesidad de descanso (es decir, aprendiendo de forma iterativa las 24 horas del día, los 7 días de la semana, los 365 días del año).
Así que, con estas ideas en mente, exploremos cómo la ciencia de los datos, el aprendizaje de las máquinas y la inteligencia artificial han ido ganando protagonismo en la comunidad empresarial.
Lo que nos resulta muy interesante es que la IA parece estar comiéndose el mundo, y hay compañías que brotan por todas partes enfocadas en aprovechar la IA para mejorar los negocios o los resultados de salud. Livongo es una ellas, una compañía de salud basada en la IA, aunque hay literalmente innumerables ejemplos.
Y el principio subyacente es el mismo en todas las industrias. Es decir, el objetivo de la IA podría compararse con el objetivo de un organismo vivo.
Como humanos, constantemente recogemos datos (entradas sensoriales, como la vista, el olfato o el oído), almacenamos datos (memorias), y usamos esos datos para predecir el futuro (es decir, esperar a que pasen los coches porque podemos predecir la muerte si entramos en el tráfico). Esta es una adaptación evolutiva que la vida se ha desarrollado a lo largo de millones de años, por lo que estamos mejor capacitados para sobrevivir y procrear con una mejor capacidad para predecir el futuro y actuar de acuerdo con esas predicciones.
En el mundo de la sanidad, la IA está creando empresas que, basándose en la analogía anterior, podrían considerarse mejor adaptadas para la supervivencia y la procreación.
En el caso de Livongo, su énfasis en la recopilación de datos, su almacenamiento y la creación de predicciones basadas en ellos reduce los costes (perpetuando la supervivencia de las empresas suscriptoras) y mejora los resultados sanitarios de sus pacientes (perpetuando la supervivencia de los pacientes como seres vivos).
Es decir, utilizar datos para predecir los resultados de salud para los organismos vivos a través del aprendizaje automático y la IA no es diferente de utilizar datos para predecir los resultados empresariales a través del aprendizaje automático y la IA, ya que las empresas pueden ser vistas como organismos vivos en sí mismos.
En el caso de un Splunk, su plataforma permite la recolección (mediante la entrada sensorial de la máquina), el almacenamiento (mediante bases de datos/índices) y las predicciones (mediante su juego de herramientas de aprendizaje automático) que permiten a sus clientes crear empresas más capaces de identificar ineficiencias, predecir resultados futuros y, en última instancia, prosperar y ganar en el siempre cambiante panorama de los negocios. Splunk hace que las empresas sean más capaces de sobrevivir en un entorno empresarial más adecuado (sin nuestros muy acomodaticios bancos centrales por lo menos).
En pocas palabras, la salud de un organismo se rige por los mismos principios que la salud de una empresa.
Cuanto mejor sea la capacidad de recopilar datos, almacenarlos y utilizarlos para crear predicciones procesables del futuro, más fácil será para esa empresa sobrevivir, prosperar y prosperar.
Aquellos sin las capacidades inteligentes mencionadas anteriormente no podrán prosperar.
Evolución y Selección Natural Capítulo 1.
Y esto se está convirtiendo en una carrera de armamento en la comunidad empresarial. Es decir, las ofertas de Splunk y Elastic serán vistas no sólo como esenciales en el futuro, sino que serán vistas como armas nucleares.
Sin estas armas en los arsenales de las empresas, las compañías que no las tengan se convertirán en irrelevantes en el escenario mundial de los negocios, al igual que los países sin armas nucleares en el siglo XX no fueron considerados superpotencias mundiales.
Las empresas del mañana deben comprar las ofertas de negocios antes mencionadas si quieren dominar en un mundo donde el poderoso aprendizaje de las máquinas y la inteligencia artificial están realmente impactando los resultados de los negocios, lo cual, como llegará a saber, creemos que está ocurriendo mientras lee este artículo.
En 2019, se crearon más de 2,5 quintillones de bytes de datos cada día en el mundo, y este número sólo está previsto que explote desde estos niveles.
"No hay manera de evitarlo: los grandes datos se hacen cada vez más grandes. Los números son asombrosos, pero no se están ralentizando. Para 2020, se estima que, por cada persona en la Tierra, se crearán 1,7 MB de datos cada segundo. En nuestra sexta edición de Data Never Sleeps, una vez más echamos un vistazo a la cantidad de datos que se están creando a nuestro alrededor cada minuto del día, y tenemos la sensación de que las cosas apenas están empezando."
¡Eso es como si cada persona en la tierra generara un archivo mp3 (una canción) cada segundo de cada día en datos!
Ahora, hay dos tipos de datos en el mundo: estructurados y no estructurados.
Los datos estructurados incluyen:
Fechas
Números de teléfono
Códigos postales
Nombres de los clientes
Inventarios de productos
Información sobre las transacciones en los puntos de venta
Los datos no estructurados incluyen:
Medios de comunicación: archivos de audio y video, imágenes.
Archivos de texto: documentos de Word, presentaciones de PowerPoint, correo electrónico, registros de chat.
Correo electrónico: hay cierta estructura interna de metadatos, por lo que a veces se llama semi-estructurada, pero el campo del mensaje no está estructurado y es difícil de analizar con las herramientas tradicionales.
Medios de comunicación social: los datos de las redes sociales como Facebook, Twitter y LinkedIn.
Datos móviles: mensajes de texto, ubicaciones.
Comunicaciones: chat, grabaciones de llamadas.
Como se puede ver a continuación, la cantidad de datos está alcanzando niveles insondables, la mayoría de los cuales no están estructurados, y sólo se está acelerando en su crecimiento.

Fuente: Seeking Alpha, M-Files.com
Las empresas están siendo bombardeadas por esta explosión de datos, y para poder manejarla y aprovecharla realmente como la empresa debería, deben emplear plataformas, como Splunk o Alteryx, para no ser víctimas de la carrera armamentística de análisis de datos que estamos experimentando actualmente.
Dicho esto, sólo estamos en los inicios del partido. De hecho, podríamos estar todavía en los vestuarios esperando para entrar al campo.
El análisis de datos ha sido profetizado como el salvador de las ineficiencias de los negocios y el gobierno durante décadas, pero hasta ahora, tenemos un puñado de compañías públicas haciendo menos de 2.500 millones de dólares en ingresos, respectivamente, en el espacio puro del análisis de datos. Por supuesto, están AWS (Amazon), Azure (Microsoft), y GCP (Google), que generan casi 100 mil millones de dólares en ingresos, una cifra que se ha logrado en sólo 10 años. Esta dinámica del mercado pone de manifiesto lo naciente que es la industria, al tiempo que sigue siendo increíblemente expansiva en las circunstancias adecuadas.
Durante décadas, la fiebre del oro del análisis de datos se suponía que iba a ocurrir en paralelo con la aceleración de la inteligencia artificial que alteraría la forma en que los humanos viven y hacen negocios.
Desde que Alan Turing creó los primeros indicios de la informática y la inteligencia artificial durante la Segunda Guerra Mundial y cuestionó la capacidad de una máquina para ser sensible, los humanos han esperado el día en que nuestros amos robóticos tomaran las riendas y empezaran a generar tanta riqueza que todos nos viéramos obligados a beber de la espiga dorada del subsidio de desempleo del gobierno.
Ahora, antes de empezar a reservar esas vacaciones en una isla griega con su cheque del gobierno patrocinado por la IA, echemos un vistazo a las dos últimas décadas para descifrar lo cerca que podríamos estar de esa realidad.
Investiguemos más a fondo.
Este artículo es interesante por muchas razones, entre ellas el hecho de que muchas empresas cotizadas pueden caer bajo su paraguas.
Por ejemplo, el acceso de Facebook a miles de millones de puntos de datos, es decir, nosotros los usuarios, le permite ser una plataforma inteligente. Los datos alimentan la inteligencia, que nos recomienda a viejos amigos de la escuela secundaria como personas con las que podríamos querer conectarnos.
En el caso de Google, ya sea que utilicemos su función de traducción o que utilicemos la búsqueda en Google, las decenas de exabytes de datos que la empresa ha reunido le permiten generar mejores y más fructíferos resultados de búsqueda. Es decir, como esencialmente tiene recuerdos de nuestras interacciones pasadas con él, puede generar resultados de búsqueda más adaptados a lo que nosotros, individualmente, necesitamos.
Es como cualquier interacción que podamos tener con otro humano. Al conocer a alguien por primera vez, nunca pudimos predecir lo que podría querer desayunar. Después de 50 encuentros con esa persona, probablemente podríamos vivir sus vidas por ellos.
No es diferente en el mundo de los grandes datos, el aprendizaje de las máquinas y la inteligencia artificial. Pero la clave son los datos. Antes del siglo XXI, los datos eran escasos, pero como el gráfico anterior demostró, los datos han proliferado y se están expandiendo exponencialmente.
En la vasta extensión de los grandes datos, el aprendizaje automático, el aprendizaje profundo y la inteligencia artificial, y sus innumerables matices, esta simple rutina de recopilación de datos seguida de un aprendizaje iterativo es la base de todo lo que hacemos.
A finales de los 90, Jeff Bezos comentó que el "www" al principio de cada dirección web en realidad significaba World Wide Wait (Espera Mundial). Por supuesto, Bezos siempre ha sido primero un científico de datos, así que ha capitalizado la industria a través de Amazon, pero es la excepción. Al resto del mundo le llevaría otras dos décadas ponerse al día con el énfasis de Jeff Bezos en la ciencia de los datos, como podemos ver a continuación.
Encontramos los siguientes gráficos de Google Trends muy reveladores:
¿Con qué frecuencia se buscó "Data Science" entre 2004 y 2020?
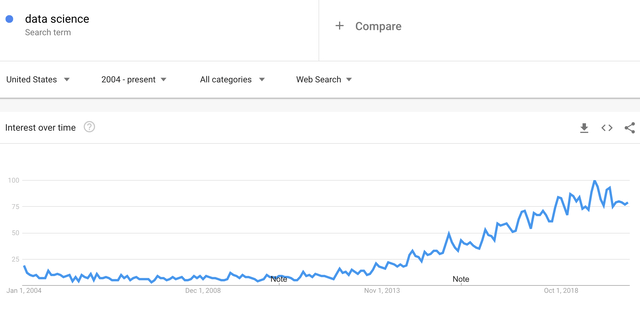
Fuente: Seeking Alpha, Google
¿Con qué frecuencia se buscó "Data Analytics" entre 2004 y 2020?

Fuente: Seeking Alpha, Google
¿Con qué frecuencia se buscó "Machine Learning" entre 2004 y 2020?
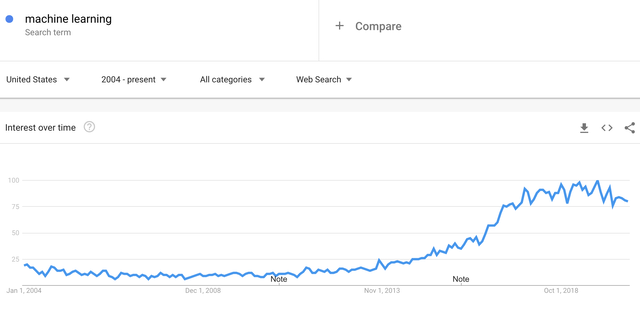
Fuente: Seeking Alpha, Google
Y estas búsquedas coinciden muy de cerca con los avances masivos que se han hecho en la inteligencia artificial (recuerde: simplemente la habilidad de recolectar datos, almacenar datos y hacer inferencias sobre los datos, al igual que una mente humana).
Desde hace décadas, compañías como Splunk, Alteryx y otras más recientes como Elastic han producido ofertas centradas en el análisis de datos.
A pesar de los casos de uso muy convincentes y la explosión total de la recopilación de datos, estas empresas se han convertido en más bien pedestres hasta ahora. Ciertamente no han experimentado un crecimiento como el del Alphabet, Amazon o Facebook.
Esta es nuestra teoría de por qué este ha sido el caso hasta ahora:
La recolección de datos en los centros de datos había sido almacenada en silos antes de la introducción de la computación en la nube para la mayoría de las empresas en la tierra, aparte de Amazon y Alphabet. La agregación de datos en enormes plataformas en la nube no se había inventado hasta principios de 2010, hace apenas 10 años.
Con el auge de la computación en la nube, a través de ofertas, como AWS, y plataformas basadas en la nube/híbridas, como Splunk y Elastic, hay ahora una poderosa centralización de datos de, potencialmente, miles de millones y billones (y un día, cuatrillones y más) de puntos de recolección en toda la tierra.
Así que recientemente se han superado grandes obstáculos, es decir, datos en silos y análisis de datos débiles/AI/ML que no pudieron generar percepciones suficientemente fuertes (léase: identificar patrones y crear pronósticos) a partir de esos datos.
No obstante, el aprendizaje de las máquinas y la IA están todavía en su infancia, pero cada día nos acercamos más a un software más poderoso que puede crear inteligencia artificial capaz de aprender de forma iterativa.
Es decir, en la actualidad tenemos miles de millones de lo que se llaman casos de uso de "IA estrecha". Nuestras computadoras y las muchas aplicaciones que procesan información para nosotros son colecciones de IA estrecha. Una calculadora básica es IA estrecha, ya que ejecuta cálculos que de otra manera tendríamos que hacer manualmente. La IA estrecha ha existido desde la creación de los primeros programas informáticos, durante los días de Alan Turing a principios y mediados del siglo XX.
La IA general aún no ha sido creada, sin embargo, la evidencia reciente sugiere que, como mínimo, nuestras capacidades de aprendizaje automático están llegando a un punto en el que la IA estrecha se está expandiendo a la IA que es realmente capaz de aprender de una manera significativa.
Estas son algunas pruebas de eso:
¿Ha usado Google translate recientemente?
Google translate solía ser completamente inútil si realmente querías comunicarte con alguien que hablaba un idioma diferente.
Hoy en día, funciona extraordinariamente bien, ya que ha tenido años para aprender de forma iterativa. Esta es una demostración pura y fácilmente accesible del aprendizaje automático. Demuestra que podemos crear software que realmente aprenda, lo que significa que cuanto más haga o analice algo, más inteligente y preciso será.
Otro ejemplo reciente de esta tecnología en acción: https://youtu.be/8dMFJpEGNLQ
Es una breve introducción a este reciente avance de la inteligencia artificial que DeepMind, que fue adquirida por Alphabet, creó para mejorar el mejor jugador de Go del mundo.
En el siguiente video, desde el minuto 7:15 al 8:20 es todo lo que se necesita para los propósitos de este artículo. Así que vean sólo esa parte por ahora, y luego vuelvan al artículo (y por supuesto, ¡vean el resto más tarde!): https://youtu.be/TnUYcTuZJpM
Lo que encontramos tan convincente de esa demostración es que la IA fue capaz de aprender de forma iterativa hasta que se convirtió en un maestro del entorno en el que se desplegó. La IA fue capaz de disparar el "disparo predictivo final" de una manera increíblemente precisa.
Las empresas aún no han aprovechado de manera significativa el análisis de datos, la IA y el aprendizaje automático, porque la capacidad de predicción ha sido débil en muchos casos de uso.
Con el aprendizaje automático avanzando rápidamente o, más bien, llegando al punto en el que se está volviendo más útil y los grandes datos se aceleran, las empresas se verán obligadas a adoptar plataformas de análisis de datos para aprovechar esta increíble tecnología.
En esencia, los negocios se convertirán en una carrera armamentística de análisis de datos y aprendizaje automático.
La adopción de plataformas desplegadas en la nube que agregan datos y permiten a los usuarios crear potentes aplicaciones de aprendizaje automático es realmente sólo el comienzo.
De hecho, creemos que se producirá una bifurcación sustancial entre las empresas que pueden crear estas inteligencias que están cribando a través de cuatrillones de bytes de datos cada día todo el día y las que no pueden permitirse el lujo de crear tales inteligencias.
No se pueden cuantificar los casos de uso de grandes datos y el correspondiente ML/AI. Cada año proliferan más casos de uso a medida que más y más dispositivos se vuelven inteligentes (léase: IA estrecha acoplada con funcionalidad de IoT, Internet de las Cosas). Con más y más dispositivos generando datos, el rango de casos de uso de la inteligencia artificial también aumentará. La necesidad de plataformas capaces de monitorizar, analizar y tomar decisiones basadas en conjuntos de datos inconcebiblemente grandes continuará aumentando dramáticamente.
Las hojas de cálculo de Excel se convertirán en algo del pasado para las empresas que se toman en serio la poderosa ciencia de los datos, por lo que Alteryx sigue siendo una inversión prometedora.
He aquí un ejemplo bastante sencillo:
En el futuro, los aeropuertos estarán totalmente gobernados por la inteligencia artificial. Desde el equipaje hasta el control del tráfico aéreo y la electricidad, y la lista sigue y sigue, los datos fluirán en una plataforma, como Splunk, donde los humanos construirán un software de IA que aprenderá estas operaciones del aeropuerto y "disparará el tiro de predicción final", por así decirlo (una referencia al vídeo sobre la inteligencia que dominó el juego).
Otro caso de uso será en la genética:
En el futuro, si no está ocurriendo ya, los científicos de datos podrán construir algoritmos que intenten probar diferentes ediciones de genes 24/7 365. Si somos capaces, en términos generales, de adivinar nuestra forma de curar la anemia falciforme hoy en día, entonces imaginemos una inteligencia de supercomputadora, en la que podríamos utilizar software para replicar un entorno genético e instruir a esa inteligencia para que intente todas las ediciones posibles del gen hasta que encuentre la solución correcta para curar la enfermedad en cuestión.
Creemos que tal inteligencia está al menos a un par de décadas de distancia, pero desarrollaremos formas suaves de ella gradualmente con el tiempo, lo que llevará a avances médicos.
Splunk, Elastic y Alteryx necesitan crear plataformas en las que los individuos estén capacitados para tomar conjuntos de datos y construir inteligencia que pueda ejecutar estos ataques de fuerza bruta en la resolución de problemas y crear inteligencia que pueda manejar todo un complejo industrial robótico, por ejemplo.
Y sabemos que están haciendo justamente eso.
El universo de análisis de datos, como hemos mencionado, es extenso. Este documental realmente destaca el grado en que Amazon es una compañía de análisis de datos pura. Es decir, alguna forma de inteligencia artificial potencia sus operaciones.
Dicho esto, buscamos compañías de análisis de datos que actúen como soluciones "off the shelf" para compañías que quieran crear una poderosa inteligencia artificial para impulsar sus negocios.
Si bien Splunk y Elastic son dos grandes maneras de jugar esta tendencia, estamos realmente en los primeros pasos de la evolución y expansión de los grandes datos, el análisis de datos y la IA. Muchas compañías que ni siquiera se anuncian como compañías de análisis de datos pueden llegar a ser las compañías de IA más avanzadas y valiosas del siglo XXI.
Amazon y Alphabet ya nos han impartido esas lecciones.
Además, en esta etapa, no deberíamos lanzarnos sobre una compañía a menos que la dirección declare expresamente que están enfocados en apalancar el ML/AI para crear un negocio que sobrevivirá durante la carrera armamentista de la IA del siglo XXI.
Artículos relacionados:
Momento de invertir en el próximo gran despertar tecnológico
Por qué la "Inteligencia Artificial" es un fraude
Considere este y otros artículos como marcos de aprendizaje y reflexión, no son recomendaciones de inversión. Si este artículo despierta su interés en el activo, el país, la compañía o el sector que hemos mencionado, debería ser el principio, no el final, de su análisis.
Lea los informes sectoriales, los informes anuales de las compañías, hable con la dirección, construya sus modelos, reafirme sus propias conclusiones, ponga a prueba nuestras suposiciones y forme las suyas propias.
Por favor, haga su propio análisis.
Utilizada por 20 millones de personas cada mes, Seeking Alpha es la mayor comunidad inversora del mundo. Impulsada por la sabiduría y la diversidad del crowdsourcing, millones de apasionados inversores se conectan diariamente para descubrir y compartir nuevas ideas de inversión, discutir las últimas noticias, debatir los méritos de las acciones y tomar decisiones de inversión bien fundadas.
Fuente / Autor: Seeking Alpha / Louis Stevens
https://seekingalpha.com/article/4381701-this-is-one-of-greatest-secular-growth-trends
Imagen: Inc.
Deja un comentario
Tu email no será publicado. Los campos requeridos están marcados con **